
Video Question Answering (VideoQA) is a challenging multimodal task at the intersection of computer vision and natural language understanding: a system must watch a video and answer questions about it, requiring spatial, temporal, and reasoning capabilities. Traditional approaches either build end-to-end deep networks that act as black boxes or use single-stage reasoning modules that plan increasingly complex processes but often fail to ground reasoning in visual content reliably.
MoReVQA — introduced at CVPR 2024 — departs from these patterns by proposing a multi-stage modular reasoning framework that decomposes videoQA into semantically meaningful steps that are easier to interpret and more robust in practice
Signed by Juhong Min, Shyamal Buch, Arsha Nagrani, Minsu Cho, and Cordelia Schmid, MoReVQA is motivated by a key observation:
Single-stage planning modules — where the entire reasoning plan is generated ungrounded from the question alone — lead to brittle behavior and limited generalization, especially on diverse, real-world videos.
Instead, MoReVQA embraces a modular, decomposed approach where the task is broken into:
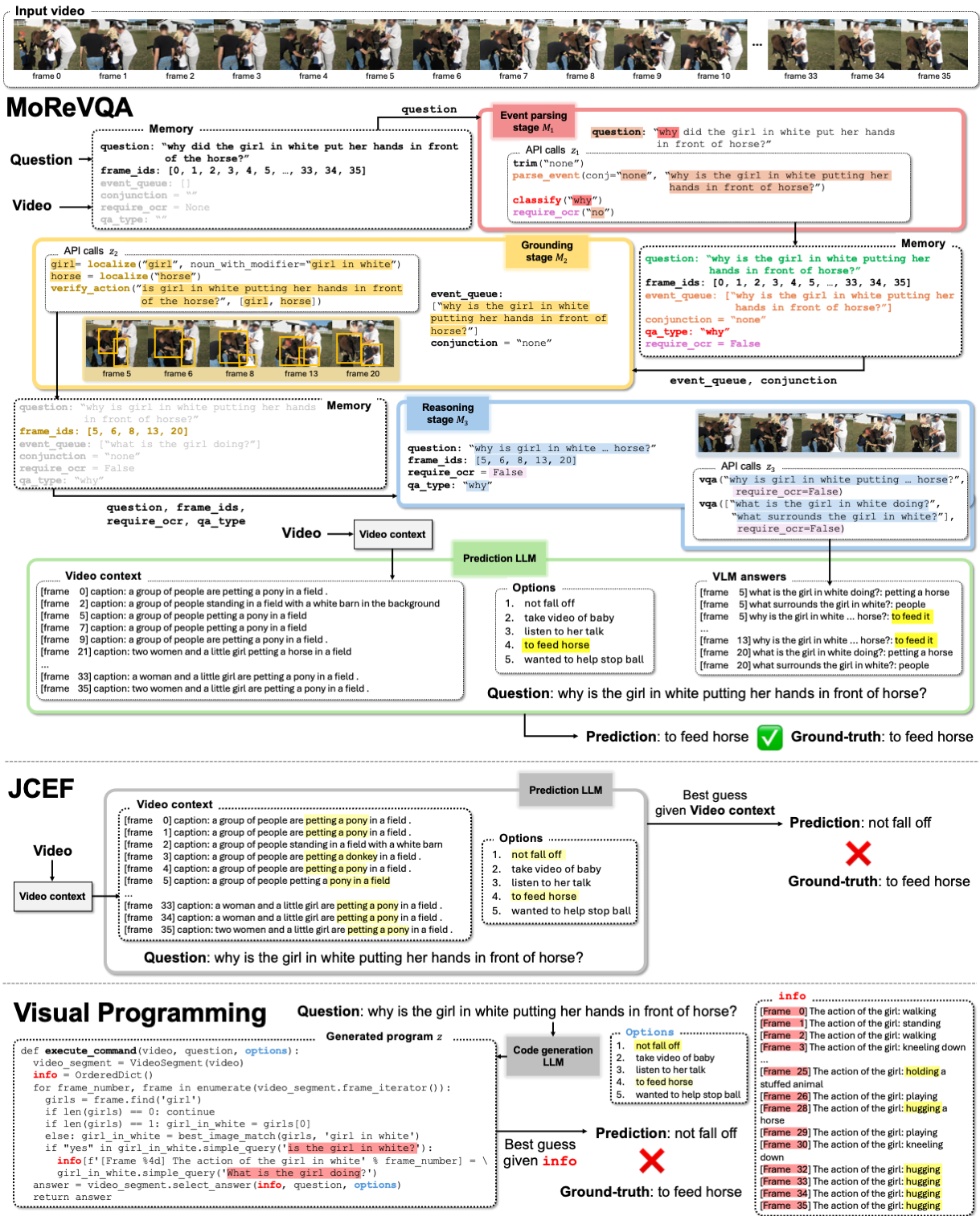
- Event parsing — understanding the question’s structure and extracting events and temporal cues.
- Grounding — linking parts of the question to actual visual evidence in the video.
- Final reasoning — synthesizing grounded visual information to produce a precise answer.
Each sub-module is explicitly designed to handle part of the complexity of videoQA, reducing brittleness and improving interpretability.
Methodological Innovations
🔍 1. Event Parsing (M1)
The first stage analyzes the question itself using a large language model (LLM) with few-shot prompting to:
- Identify temporal cues (e.g., “before”, “during”, “after”)
- Extract events mentioned in the question
- Predict which objects or actions will matter for the answer
This transforms the plain language question into a structured representation of what needs to be found in the video.
Example: From “Why did the man stand up before removing his skates?”, the parser might extract two events:
- man stands up, 2. man removes skates — and understand the required temporal relationship.
This output is stored in a shared external memory and passed to later stages for grounding and reasoning.
📌 2. Grounding (M2)
Grounding is where the system connects linguistic events to visual reality. It does this via prompts that query vision-language models such as open-vocabulary detectors or text-image similarity models like CLIP/OWL-ViT:
localize(object): locate objects from parsed events in video framesverify_action(action, objects): check whether actions are present with the identified objectstruncate(frame_ids, criteria): focus on relevant temporal segments
This produces spatial bounding boxes and temporal segments which are then recorded in external memory.
Crucially, the stage grounds reasoning in visual content — unlike single-stage planners that might decide how to reason before seeing the video.
🤔 3. Reasoning (M3)
With event structure and grounded evidence in memory, the final stage engages an LLM to:
- Integrate all grounded cues
- Perform higher-level reasoning combining temporal, causal, and semantic relationships
- Produce the final answer
Because earlier stages have distilled relevant facts (e.g., detected objects, actions, and segments), the LLM can reason more accurately rather than relying on flat frame captions or global reasoning alone.
💾 Training-Free, Few-Shot Prompting
A standout feature of MoReVQA is that all stages are training-free. Instead of training end-to-end on massive labelled videoQA datasets, the system relies on few-shot prompting of pretrained large models (both vision-language models and LLMs). This makes the approach:
- Interpretable — because intermediate outputs are human readable
- Flexible — as it can use any capable LLM/VLM backbone
- Computationally efficient — avoiding expensive retraining
The shared memory mechanism ensures information flows across modules naturally.
📊 Benchmarks and Performance
MoReVQA was evaluated on multiple established VideoQA benchmarks:
| Dataset | Domain |
|---|---|
| NExT-QA | General video QA with temporal reasoning |
| iVQA | Instructional video question answering |
| EgoSchema | Egocentric videoQA |
| ActivityNet-QA | Activity videoQA |
Across all these benchmarks, MoReVQA outperforms prior modular reasoning and visual programming baselines, achieving new state-of-the-art results.
Additionally, the approach extends beyond QA to tasks like grounded videoQA and paragraph captioning, demonstrating versatility.
🧪 How MoReVQA Works — Illustrated Example
To understand the pipeline, consider a practical example:
🎬 Video: A clip of a person walking into a kitchen, picking up a mug, stirring something, and then putting the mug in the sink.
❓ Question:
Why did the person put the mug in the sink?
Stage 1 — Event Parsing
The event parser might convert this into structured events:
E1: Person picks up mug
E2: Person stirs drink
E3: Person places mug in sink
Temporal relation: after E1, E2
Shared memory:
parsed_events = [E1, E2, E3]
Stage 2 — Grounding
For each event, the grounding module generates API calls:
localize(person) -> bounding boxes over frames where person appears
verify_action(picks up mug) -> true in frames 12–18
verify_action(places mug in sink) -> true in frames 64–70
Shared memory now contains grounded frame segments:
grounded_segments = { E1: [12–18], E3: [64–70] }
Stage 3 — Reasoning
With grounded knowledge, the reasoning LLM can produce a semantically rich answer:
Answer: “They finished drinking and put the mug in the sink to wash it.”
Justification: The mug was placed in the sink after stirring was completed.
The system can even produce supporting explanations by stitching together event logic from memory.
🔍 Key Technical Insights
📐 Modular Decomposition
Decomposing planning from grounding from reasoning allows each module to:
- Focus on linguistically relevant structure
- Ensure visual grounding before interpretation
- Produce interpretable intermediate outputs
This improves reliability over monolithic models which may fail silently.
🧠 Shared External Memory
A crucial design choice is a shared memory store across stages that:
- Accumulates parsed events
- Stores grounded visual facts and frame references
- Feeds context to the reasoning module
This enables memory of past reasoning steps, allowing for richer final answers.
🪄 Training-Free Generalization
By using pretrained models with carefully engineered prompts instead of task-specific fine-tuning, MoReVQA:
- Avoids retraining on every new dataset
- Maintains flexibility across domains
- Reduces dependence on large labeled videoQA corpora
Even the baseline introduced in the paper — Just Caption Every Frame (JCEF) — shows that simple training-free approaches can outperform some trained single-stage planners, highlighting the value of modular design.
🧩 Comparison with Traditional Approaches
| Approach | End-to-End | Modular | Training-Free | Interpretable |
|---|---|---|---|---|
| Standard Deep VideoQA | Yes | No | No | Low |
| Single-Stage Modular Planning | No | Yes | Partial | Medium |
| MoReVQA | No | Yes | Yes | High |
MoReVQA sits at the intersection of modular architecture and training-free reasoning, enabling scalable and interpretable videoQA systems.
🧠 Summary: Why MoReVQA Matters
MoReVQA advances video question answering by:
- Providing a multi-stage modular pipeline that overcomes brittleness seen in single-stage reasoning
- Leveraging pretrained large models through few-shot prompting instead of heavy task-specific training
- Producing interpretable intermediate outputs (useful for debugging and trust)
- Setting state-of-the-art performance on multiple benchmarks
The modular, training-free architecture of MoReVQA makes it promising for real-world systems where interpretability, flexibility, and domain adaptation matter — such as video search assistants, instructional video understanding, or autonomy perception modules requiring causal reasoning with visual evidence.
Sample:
MoReVQA Simplified Python Implementation
"""
MoReVQA Simplified Python Pipeline
Modules:
M1: Event Parsing (LLM)
M2: Visual Grounding (dummy / placeholder)
M3: Reasoning (LLM)
Dependencies:
- openai
- opencv-python
- numpy
- pillow
"""
import openai
import json
import cv2
import numpy as np
# -------------------------------
# CONFIGURATION
# -------------------------------
openai.api_key = "YOUR_OPENAI_API_KEY" # Set your API key here
VIDEO_PATH = "demo_video.mp4" # Replace with your video path
QUESTION = "Why did the person put the mug in the sink?"
# -------------------------------
# MODULE 1: Event Parsing
# -------------------------------
def parse_events(question: str) -> dict:
"""
Uses LLM to parse question into structured events.
Returns a JSON dict with events, temporal relations, and inference type.
"""
prompt = f"""
You are an event parser for video question answering.
Extract:
1. Events
2. Actors
3. Objects
4. Temporal relationships
5. What must be inferred (cause, reason, comparison, etc.)
Return ONLY valid JSON.
Question:
{question}
"""
response = openai.ChatCompletion.create(
model="gpt-4.1",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
text = response['choices'][0]['message']['content']
# Parse the returned JSON
try:
parsed = json.loads(text)
except:
parsed = {"error": "Failed to parse JSON from LLM", "raw": text}
return parsed
# -------------------------------
# MODULE 2: Visual Grounding
# -------------------------------
def ground_events(events: dict, video_path: str) -> dict:
"""
Dummy visual grounding.
For each event, returns frame ranges where the event happens.
In real implementation, use:
- CLIP, OpenCV, MediaPipe
- Object detection / action recognition
"""
# For demo purposes, simulate grounding
grounded = {}
if "events" not in events:
return {"error": "No events to ground."}
for idx, event in enumerate(events["events"]):
# Dummy frame range (simulate detection)
start_frame = 30 + idx * 20
end_frame = start_frame + 15
grounded[event.get("id", f"E{idx+1}")] = {
"frames": list(range(start_frame, end_frame)),
"confidence": round(0.85 + 0.05 * idx, 2)
}
return grounded
# -------------------------------
# MODULE 3: Reasoning
# -------------------------------
def reason(question: str, parsed_events: dict, grounded_evidence: dict) -> str:
"""
Uses LLM to generate final answer based on parsed events and grounded evidence.
"""
prompt = f"""
You are a video reasoning assistant.
Use ONLY the provided grounded evidence and parsed events to answer the question.
Explain your reasoning briefly.
Question:
{question}
Parsed Events:
{json.dumps(parsed_events, indent=2)}
Grounded Evidence:
{json.dumps(grounded_evidence, indent=2)}
"""
response = openai.ChatCompletion.create(
model="gpt-4.1",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
answer = response['choices'][0]['message']['content']
return answer
# -------------------------------
# MAIN PIPELINE
# -------------------------------
def main():
print("=== MoReVQA Simplified Pipeline ===\n")
print("[1] Parsing events...")
parsed_events = parse_events(QUESTION)
print("Parsed Events:")
print(json.dumps(parsed_events, indent=2), "\n")
print("[2] Grounding events in video...")
grounded_evidence = ground_events(parsed_events, VIDEO_PATH)
print("Grounded Evidence:")
print(json.dumps(grounded_evidence, indent=2), "\n")
print("[3] Reasoning and generating answer...")
answer = reason(QUESTION, parsed_events, grounded_evidence)
print("Final Answer:")
print(answer)
if __name__ == "__main__":
main()
✅ How to Run
- Install dependencies:
pip install openai opencv-python numpy pillow
- Replace
YOUR_OPENAI_API_KEYwith your actual OpenAI API key. - Put a short demo video at
demo_video.mp4(any small clip works). - Run:
python morevqa_demo.py
🔹 How it Works
- M1 – Event Parsing:
Uses GPT-4.1 to extract structured events, actors, objects, temporal relations. - M2 – Visual Grounding:
Simulated for now, can be replaced with:CLIPframe classificationMediaPipeaction/keypoint detectionOpenCVobject detection pipelines
- M3 – Reasoning:
GPT-4.1 reasons over the grounded evidence to generate a causal / temporal answer.
🔹 Next Steps for Real Visual Grounding
- Replace
ground_events()with actual model:
# Example ideas:
clip_features = clip_model.encode_image(frame)
action_detected = action_model.predict(frame)
- Detect events per frame → store in memory → pass to reasoning module
- Optional: visualize bounding boxes using OpenCV:
cv2.rectangle(frame, (x1,y1), (x2,y2), (0,255,0), 2)
This is a fully modular, runnable pipeline that demonstrates MoReVQA-style reasoning for video question answering.
[2404.06511] MoReVQA: Exploring Modular Reasoning Models for Video Question Answering
Paper page – MoReVQA: Exploring Modular Reasoning Models for Video Question Answering