
Several companies and research institutions have been developing large language models (LLMs) for cars, with a focus on enhancing the in-car experience and autonomous driving capabilities. These LLMs are used for voice interactions, infotainment systems, driver assistance, and decision-making in autonomous driving. Here are some notable LLMs developed specifically for the automotive sector:
- Tesla’s Dojo Supercomputer:
Purpose: Used to train models for Tesla’s Full Self-Driving (FSD) technology. While not an LLM in the traditional sense, Tesla’s Dojo processes massive amounts of data from its fleet to improve decision-making and autonomous driving capabilities. It is expected that advanced LLMs could be integrated into this system to improve human-machine interactions inside the car.
Focus: Autonomous driving and decision-making.
- Mercedes-Benz and OpenAI Collaboration:
Purpose: Mercedes-Benz partnered with OpenAI to integrate GPT-3 into its MBUX (Mercedes-Benz User Experience) infotainment system. This integration allows drivers to interact with the vehicle more naturally through voice commands, asking the car for recommendations, route guidance, and information on various topics.
Focus: Voice-controlled AI for in-car infotainment and interaction.
- Amazon Alexa for Automotive:
Purpose: Amazon has adapted its Alexa voice assistant, which is built on an LLM, for use in cars. It supports voice commands for navigation, media control, smart home integration, and more.
Focus: Voice assistance and in-car infotainment.
- NVIDIA DRIVE:
Purpose: NVIDIA uses its DRIVE platform, which includes AI and LLM models, to support autonomous driving. It integrates various forms of AI, including natural language processing (NLP) for interacting with drivers.
Focus: Autonomous driving, decision-making, and in-car interactions.
- Cerence AI:
Purpose: Cerence specializes in automotive AI solutions, including voice recognition and natural language understanding. It powers conversational AI in many vehicles, enabling drivers to communicate with their cars via voice commands and enhancing the in-car experience.
Focus: Conversational AI and infotainment for vehicles.
- BMW Intelligent Personal Assistant:
Purpose: BMW has integrated a voice-controlled assistant powered by AI models into its vehicles. It allows drivers to control various aspects of the car, including navigation, climate control, and media, using natural language.
Focus: In-car voice interaction and personalization.
- Ford SYNC 4 with Natural Language Processing:
Purpose: Ford’s SYNC 4 infotainment system includes an NLP-powered voice assistant, which helps drivers manage navigation, media, and phone calls through natural speech.
Focus: Voice-controlled assistant for in-car tasks.
- General Motors’ Super Cruise with AI:
Purpose: GM’s Super Cruise uses AI, including LLM-like capabilities for voice commands, to enhance hands-free driving assistance and offer driver support.
Focus: Autonomous driving and driver support with voice interaction capabilities.
These LLMs and AI models help improve the user experience in vehicles, offering more natural interactions through voice commands, enhanced infotainment, and even autonomous driving features.
Geely develops large language model for in-vehicle infotainment – Geely develops large language model for in-vehicle infotainment | Automotive Dive
LLM key Concepts – basic (Coursey – Think Autonomous
3 key ideas:
- Tokenization
- Transformers
- Processing Language
Tokenization
In ChatGPT, you input a piece of text, and it returns text, right? Well, what’s actually happening is that your text is first converted into tokens.
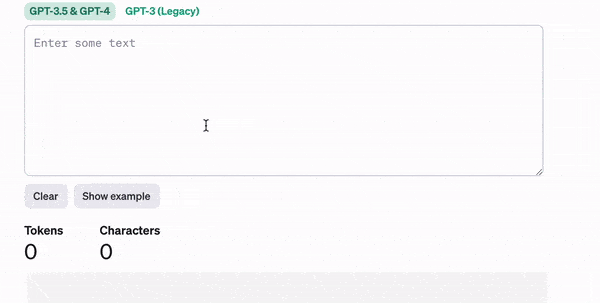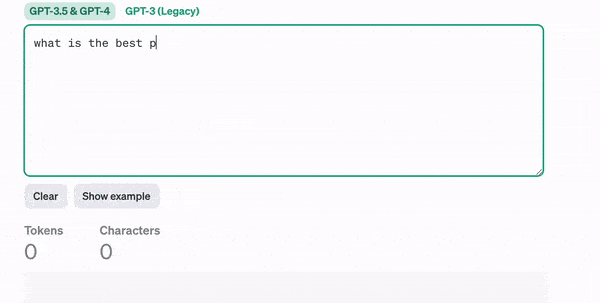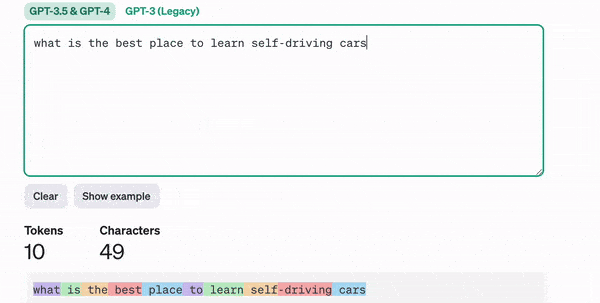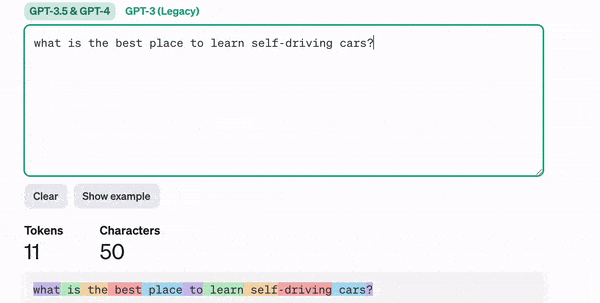
But what’s a token? You might ask. Well, a token can correspond to a word, a character, or anything we want. Think about it — if you are to send a sentence to a neural network, you didn’t plan on sending actual words, did you?
The input of a neural network is always a number, so you need to convert your text into numbers; this is tokenization.
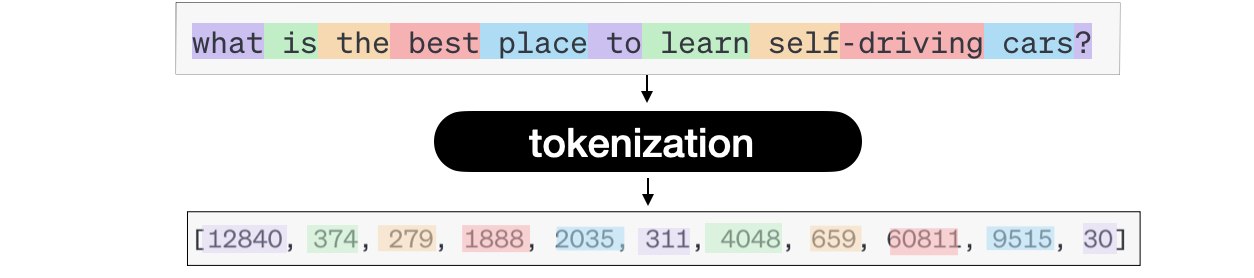
Depending on the model (ChatGPT, LLAMA, etc…), a token can mean different things: a word, a subword, or even a character. We could take the English vocabulary and define these as words or take parts of words (subwords) and handle even more complex inputs. For example, the word « a » could be token 1, and the word « abracadabra » would be token 121.
Transformers
Now that we understand how to convert a sentence into a series of numbers, we can send that series into our neural network! At a high level, we have the following structure:
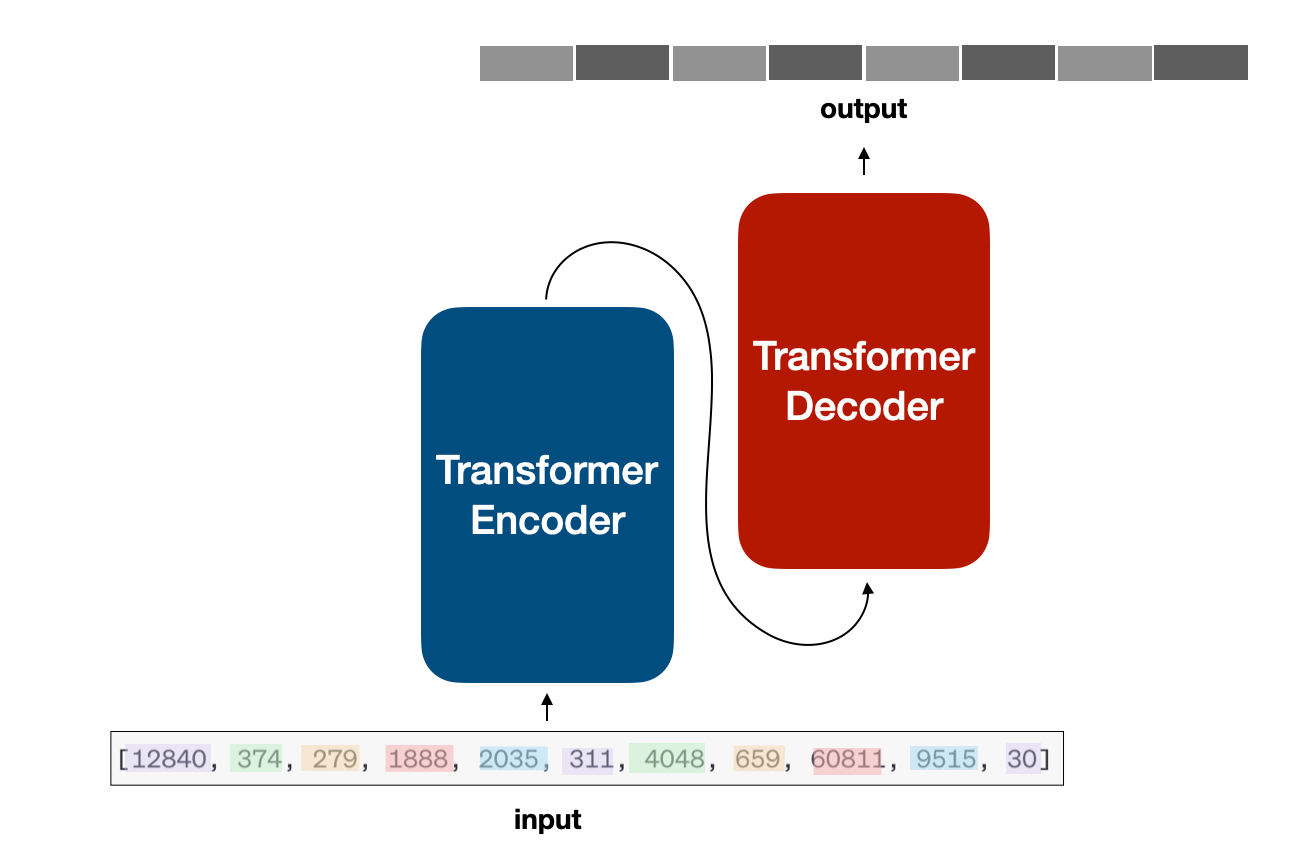
If you start looking around, you will see that some models are based on an encoder-decoder architecture, some others are purely encoder-based, and others, like GPT, are purely decoder-based.
Whatever the case, they all share the core Transformer blocks: multi-head attention, layer normalization, addition and concatenation, blocks, cross-attention, etc…
This is just a series of attention blocks getting you to the output. So how does this word prediction work?
The output/ Next-Word Prediction
The Encoder learns features and understands context… But what does the decoder do? In the case of object detection, the decoder is predicting bounding boxes. In the case of segmentation, the decoder is predicting segmentation masks. What about here?
In our case, the decoder is trying to generate a series of words; we call this task “next-word prediction”.
Of course, it does it similarly by predicting numbers or tokens. This characterizes our full model as shown below,
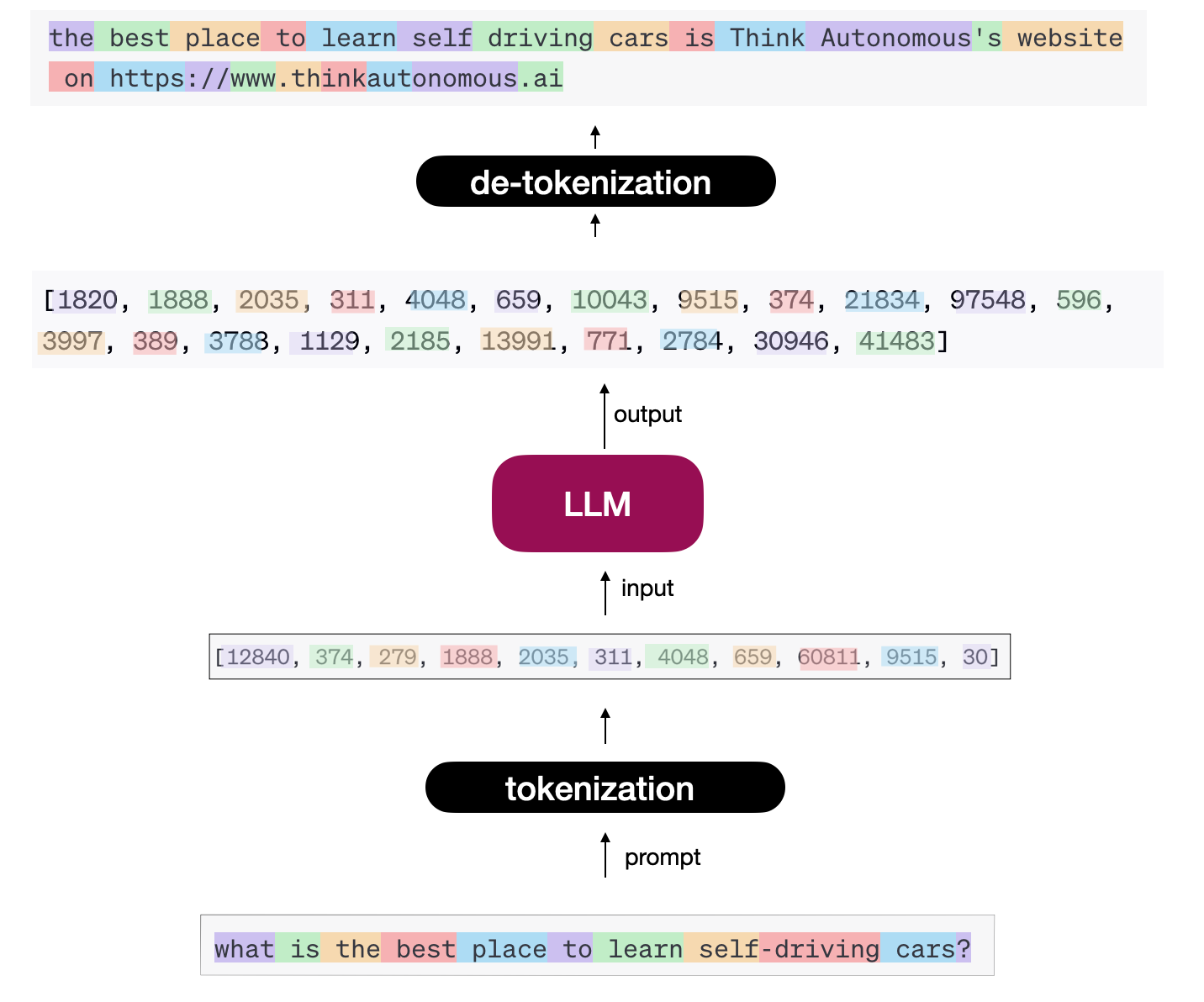
Now, there are many “concepts” that you should learn on top of this intro: everything Transformer and Attention related, but also few-shot learning, pretraining, finetuning, and more…