
Audiobook platform offers multilingual expressive TTS, voice cloning, emotional tagging ([whispers], [sighs]), and multi-speaker dialogue capabilities, additionally it has virtual assistant, game narration system, or music tool.
Generate high-quality AI audio for your audiobooks, videos and podcasts
Audiobooks
Create high-quality multi-character audiobooks. Upload your ePub or PDF, select your characters, direct the delivery and then publish.
Video voiceovers
Choose the perfect voice for your video or clone your own voice. Then generate high-quality voice overs for ads, shorts or feature-length films.
Dubbed videos
Translate your content into 30+ languages while maintaining the voice of the speaker. Dub it in 1-click or have full-control over translation and delivery with Dubbing Studio.
Podcasts
Voice Isolator turns any recording into studio quality. Or use Text to Speech to generate short sections with your own voice or entire podcasts with multiple speakers.
Key Offerings at a Glance
| Offering | Description & Use Cases |
|---|---|
| Text-to-Speech (TTS) Models | Multilingual v2 (high fidelity), Flash v2.5 (ultra-low latency), v3 (expressive controls) |
| Voice Cloning | Instant and professional voice cloning from brief samples. |
| Voice Changer | Transform voice with emotion and style control. |
| Agents Platform | Build voice agents with advanced dialog management and LLM integration. |
| Speech-to-Text (Scribe) | Accurate transcription with diarization and timestamps. |
| AI Dubbing & Studio | Multilingual dubbing and long-form audio production tools. |
| Voice Library & Monetization | Publish and earn from shared cloned voices. |
| AI Music Generator | Generate original music with full commercial rights. |
| AI Speech Classifier & Safety | Detect synthetic speech and protect against misuse. |
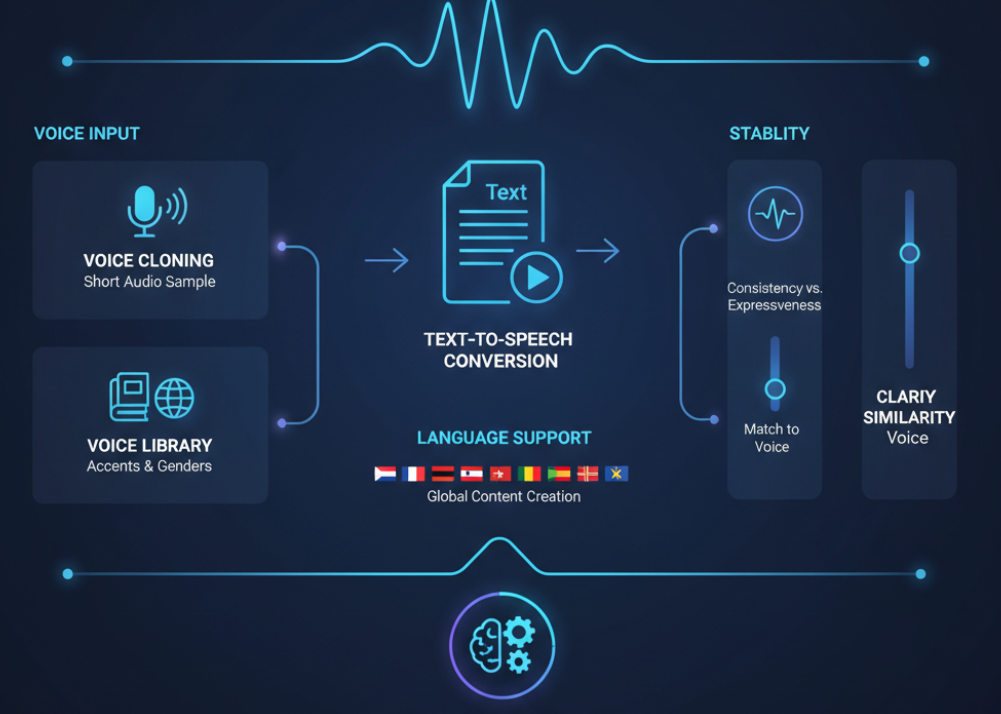
ElevenLabs Technical Architecture (Conceptual Diagram)
1. Input Layer
- Text Input: Raw script, dialogue, or prompts.
- Voice Sample (for cloning): A short recorded snippet for personalized voice creation.
2. Preprocessing
- Text Processing: Natural Language Processing (NLP) & context analysis to interpret meaning, sentiment, and pacing.
- Audio Preprocessing: (For voice samples) noise reduction and normalization, possibly using Voice Isolator
3. Core Audio Generation Pipeline
- Model Selection:
- Multilingual v2 – High-fidelity, emotionally rich, 29 languages
- Flash v2.5 – Ultra-low latency (≈75 ms), supports 32 languages
- Eleven v3 (Alpha) – Most expressive, supports 70+ languages, audio tags control, multi-speaker dialogue
- Voice Cloning Module:
- Instant or Professional – Produces a clone voice from short audio samples.
- Voice Changer Module:
- Transforms one speaker’s voice into another; customizable emotion, inflection, tone
4. Additional Features & Tools
- Agents Platform:
- Conversational AI agents with voice—supporting multi-turn dialogue, function calling, integration with LLMs, phone/telephony support, low latency, multi-language
- Dubbing & Studio:
- AI-driven dubbing with emotion and intonation preservation across languages
- Studio tools for long-form audio content like audiobooks
- Scribe (Speech-to-Text):
- Accurate transcription with speaker diarization and timestamps
- Voice Library & Payouts:
- Community-driven voice marketplace. Creators can share cloned voices and earn passive income in exchange for use
- AI Music Generator:
- Prompt-based, royalty-free AI music generation with commercial rights, supporting multiple genres and languages. Includes editing and structure control
- Safety & Moderation:
- AI Speech Classifier detects synthetic audio; provenance tracking; usage monitoring and moderation safeguard misuse
5. SDKs & APIs
- Programmable access via Text-to-Speech, Speech-to-Text, Voice Cloning, Voice Changer, Agents APIs, with Python and TypeScript SDKs; enterprise-grade compliance (GDPR, SOC II)
6. Deployment & Infrastructure
- Low-Latency Serving: Optimized models like Flash v2.5 for conversational responsiveness
- Scalable Backend: Supports real-time generation, cloning, and agent orchestration at scale.