
A generative adversarial network, or GAN, is a deep neural network framework which is able to learn from a set of training data and generate new data with the same characteristics as the training data.
Generative modeling is an unsupervised learning task in machine learning that involves automatically discovering and learning the regularities or patterns in input data in such a way that the model can be used to generate or output new examples that plausibly could have been drawn from the original dataset.
Deep neural networks are used mainly for supervised learning: classification or regression. Generative Adversarial Networks or GANs, however, use neural networks for a very different purpose: Generative modeling.
Generative modeling is an unsupervised learning task in machine learning that involves automatically discovering and learning the regularities or patterns in input data in such a way that the model can be used to generate or output new examples that plausibly could have been drawn from the original dataset.
The GAN model architecture involves two sub-models: a generator model for generating new examples and a discriminator model for classifying whether generated examples are real, from the domain, or fake, generated by the generator model.
Generator. Model that is used to generate new plausible examples from the problem domain.
Discriminator. Model that is used to classify examples as real (from the domain) or fake (generated).
GANs are a clever way of training a generative model by framing the problem as a supervised learning problem with two sub-models: the generator model that we train to generate new examples, and the discriminator model that tries to classify examples as either real (from the domain) or fake (generated). The two models are trained together in a zero-sum game, adversarial, until the discriminator model is fooled about half the time, meaning the generator model is generating plausible examples.
GANs are an exciting and rapidly changing field, delivering on the promise of generative models in their ability to generate realistic examples across a range of problem domains, most notably in image-to-image translation tasks such as translating photos of summer to winter or day to night, and in generating photorealistic photos of objects, scenes, and people that even humans cannot tell are fake.
There are two neural networks: a Generator and a Discriminator. The generator generates a “fake” sample given a random vector/matrix, and the discriminator attempts to detect whether a given sample is “real” (picked from the training data) or “fake” (generated by the generator). Training happens in tandem: we train the discriminator for a few epochs, then train the generator for a few epochs, and repeat. This way both the generator and the discriminator get better at doing their jobs.
Examples of Generative Models
Naive Bayes is an example of a generative model that is more often used as a discriminative model.
For example, Naive Bayes works by summarizing the probability distribution of each input variable and the output class. When a prediction is made, the probability for each possible outcome is calculated for each variable, the independent probabilities are combined, and the most likely outcome is predicted. Used in reverse, the probability distributions for each variable can be sampled to generate new plausible (independent) feature values.
Other examples of generative models include Latent Dirichlet Allocation, or LDA, and the Gaussian Mixture Model, or GMM.
Deep learning methods can be used as generative models. Two popular examples include the Restricted Boltzmann Machine, or RBM, and the Deep Belief Network, or DBN.
Two modern examples of deep learning generative modeling algorithms include the Variational Autoencoder, or VAE, and the Generative Adversarial Network, or GAN.
Sample projects :
Medical Image Synthesis using GANs for Pulmonary Chest X-rays
As the field of AI is progressing at the speed of light, dedicated research has been going to find novel ways to exploit the sophisticated deep learning models in the field of medical science. It will not only help in taking the burden off the shoulders of frontline medical service providers but also help in tackling situations like pandemics/epidemics more effectively. Many CNNs have reported state-of-the-art performance in predicting the correct diagnosis through radiography and CT scans. But the amount of data available for training these models is limited, which increases the possibilities of model overfitting. The dataset collection and annotation for medical imaging is quite tedious and expensive. It is highly prone to bias and labelling errors as multiple radiologists participate as annotators, and no two people are known to think the same way, especially in ambiguous cases. Is there an effective way to overcome these limitations? YES! Synthetic data generation based on the existing training data.
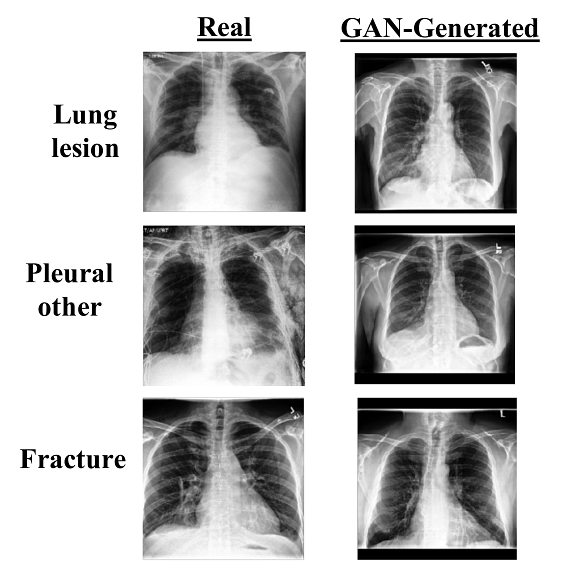
Fig. Data Augmentation of Chest X-Ray scans using GANs (Source)
Traditional data augmentation techniques include manipulation of brightness, contrast, sharpness, blurriness, etc. It is effective for simple classification tasks but not for medical imaging as it might distort the scans. We need something more intelligent like GANs. The objective is to train the generator model to generate unseen scans using the hidden underlying features of the train dataset. Multiple GAN architectures can be used like DCGAN, pix2pix, StarGAN, etc.
Use the Chest X-Ray Images dataset to try your hands-on on this gan project idea.
Build Face Aging Application using Face Synthesis
Who doesn’t want to know how we would look in our 60’s or 70’s when we would be all frail and wrinkly? While we don’t have Professor Trelawney’s magical crystal ball to foresee the future, we can definitely use generative modelling to predict what we might look like in the future. Using cGANs or Conditional GANs, we can render a face with natural ageing aesthetically blended. It is particularly helpful in searching for abducted children. The search team has to, unfortunately, abort the search mission as time passes because they can no longer use the old pictures. We can try to predict how their faces might look after so many years and continue searching for them.

Fig. Face Aging over the time while preserving identities (Source)
cGANs are an extended form of GANs that lets you generate images with certain attributes. This conditional information is passed to both generator and discriminator models, which can be anything like age, gender, etc.
You can download the dataset from IMDB-WIKI.
Colourizing Black and White Images using GANs
Image Colorization is an interesting gan project to work on. We all have some old photographs and reels which were shot in the times when colored filmography was a talk of the future. Wouldn’t it be amazing if you can colorize those black and white images bringing them back to life?
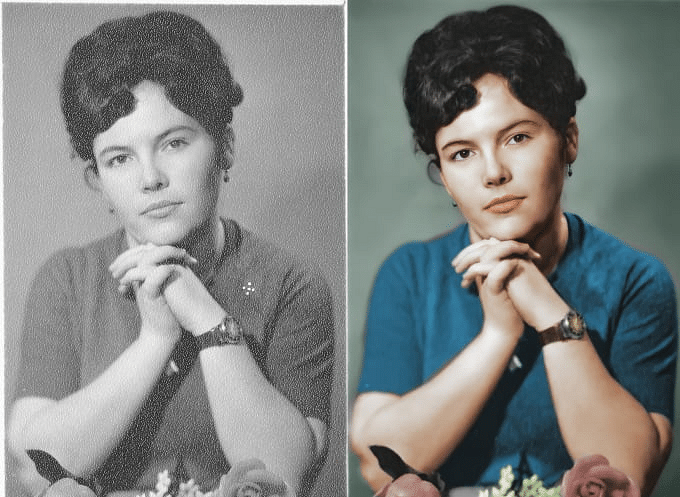
Fig. Monochrome to Colorized Images (Source)
Colorization is often defined as the process to map monochromes to the closest colors possible. Before deep learning, color reference images were used in combination with human intelligence to colorize images or videos. It was a long and tedious process and often erroneous as well. Then deep learning came into existence, and many researchers began exploiting the power of CNNs to understand the hidden patterns for colourizing a grayscale image. It was a huge achievement but still had a lot of scope for improvement. Now, with the emergence of GANs, researchers have managed to achieve more photorealistic colourized images. To experiment and play around with GANs for this project, you can use the Image Colorization dataset on Kaggle.
Satellite Image to Google Map Image-to-Image Translation using DualGANs
This is another image-to-image translation task but relatively tougher due to its detail-oriented nature. The dataset consists of pairs of Satellite images of New York and their Google Maps equivalent translations. Electronic maps play a very important role in the navigation planning of autonomous vehicles. Creating them is a very time-consuming and laborious task as it requires extensive field visits and surveys. It is also not very accurate, but artificial intelligence has achieved promising results in this field.
Typically it is a paired image-to-image translation task but GAN models like DualGAN, CycleGAN which support unpaired image-to-image translation, have reported competitive results as compared to pix2pix and GAN.

Fig. Satellite Image v/s Google Maps translation (Source)
For training the GAN, you can find the dataset Satellite to Google Maps Dataset. You can further extend this cool gan project to train the model on historical maps like the cities Jerusalem, Babylon, Rome, etc.
Removing Unwanted Noises from Real Scene Images using GANs
Ever clicked a picture with your mobile of the perfect sunset with just the right amount of reds and yellows? But when you looked at the picture, it was too grainy in texture, spoiling the quality of the capture. It could have been the next Instagram viral picture, but now you can’t show it to anyone. Well, nothing to worry about. GANs are here to your rescue.
This grainy texture of the image is known as noise. While some minimal amount of noise is present in every clicked picture, sometimes very prominent due to external sources of interference, malfunctioning camera sensors, poor lighting conditions, etc. The process of removing noise from images is known as Image Denoising.

Fig. Denoising the images using AI (Source)
Denoising images become particularly important if the data collected is for training an ML/DL model, as poor quality images will lead to poor model performance. There are a lot of computer vision use cases where real-scene images are captured for example, semantic segmentation of scene, low light object detection, image analysis on CCTV camera feed, etc. It can also help restore the images that have degraded over time or were clicked with old low-quality cameras. GANs is one of the ways to resolve this problem. For training the model, you can use the very popular SIDD or Smartphone Image Denoising Dataset for training the model. It contains ~30,000 noisy images from 10 scenes under different lighting conditions using five different smartphones.
Intent Classification using GAN-BERT
Intent Classification is a common Natural Language Processing or NLP problem where written text or audio input is fed to the model, and the model predicts the goal/intent of the user. It is most useful when we are building a chatbot. Understanding the intent behind a message that the user sent is important before generating an appropriate response.
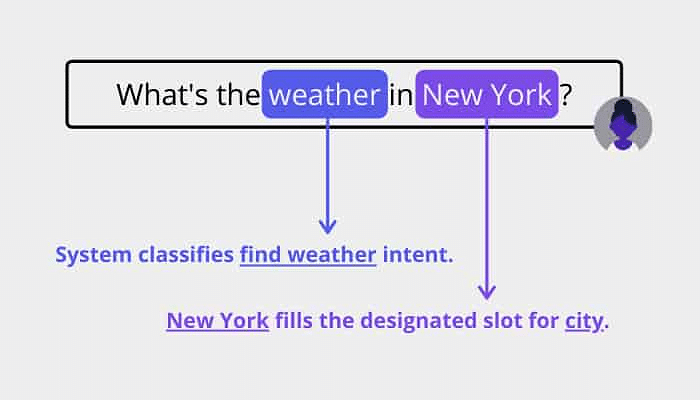
Fig. Example of Intent Classification (Source)
For e.g., A user is interacting with a chatbot on an e-commerce website and sends a message like “I wanted to buy a pair of Adidas sports shoes, how much will it cost roughly?” The intent behind this message can be identified as “Information Needed” & “Interested”. Based on the identified intent, a response/action can be triggered for the user.
Since we are dealing with textual data here, we can make use of BERT embeddings to generate context-aware text representations. While transformer models like BERT are very powerful, to exploit them to the fullest, one needs labelled data in huge numbers, which is not always feasible. One way to approach this problem can be to combine the labelled and unlabeled data together to form the training dataset. This is known as “semi-supervised classification”. Sounds interesting – no? You can combine the prowess of BERT with GANs to leverage the best of both worlds for this project.
The dataset for this project is CLINC150. This file contains 150 “in-scope” intent classes, each with 100 train, 20 validation, and 30 test samples. What makes working with this dataset challenging is the “out-of-scope” samples, i.e. the samples which do not lie within the dataset supported intent classes.
________________________________________
Generate New Human Poses using Deformable GANs
Want to challenge yourself? Try your hands-on this gan project idea. Given a human image and a target pose, you will be required to synthesize that human in the target pose. It is an unpaired image to image translation where you have two sets of unrelated training data: human figures and target poses.
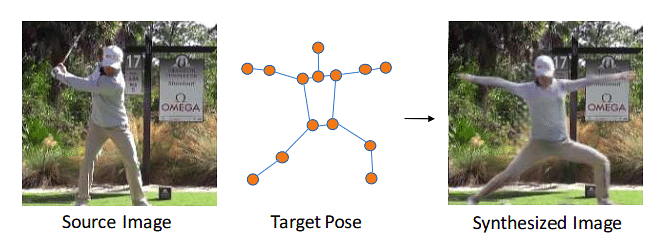
Fig. Synthesize Image with source human figure and target pose
The task is quite complicated as in the synthesized image, the details related to human appearance andthe background of the source image needs to be replicated convincingly. The general approach taken by the researchers to solve this problem is to deal with the human figure and the background separately. First, the foreground object or human figure is extracted from the image and translated to the desired pose. Then the gaps in the background are filled by synthesizing the relevant texture. They are then combined together to form the target image. A special type of GANs such as Deformable GANs is used for performing such tasks. In the real world, this application of GAN finds usage in the fashion industry, where you can generate synthetic pictures of models in different poses on demand.
Use the Pose-Transfer dataset to work on this GAN project idea.
2. Create a Text-to-Image synthesizer using ST-GANs
Generating photorealistic images based on the textual description is an exciting as well as a very challenging problem. GANs have struggled to synthesize photorealistic images based on other images provided as input. In this task, the only input given is a textual description of the image where many details of the expected/target can be ambiguous, and the model is expected to make assumptions of its own. Details and finesse become a major problem in the cases where high-resolution images need to be generated. Generalizing the images for different text descriptions can be a challenge as well. The researchers have solved this problem with the help of StackGANs or ST-GANs. In this architecture, two GANs are stacked on top of each other.

Fig. Generate the image using textual description
The dataset which you can use for training this model can be found at Oxford Flowers-102 Dataset. It contains approximately 8000 images of 102 different categories and 10 different captions as image descriptions. It covers a lot of variety in the way images can be described by different humans.
3. Abstractive Text Summarizer using GANs
Text Summarization task is of two types namely: 1) Extractive Text Summarization 2) Abstractive Text Summarization. Extractive Text Summarization is a relatively simple task where from a long text, we have to extract the sentences which are the best representation of the text. Abstractive Text Summarization on the other hand is challenging as we have to paraphrase the long text to capture the main ideas in a short text. It does not necessarily contain sentences or even words from the original text. Researchers have struggled with this problem for years and when state-of-the-art models using sequence-to-sequence are not as perfect as expected for the task.

Fig. Abstractive Summarization Idea (Source)
GANs have managed to achieve exemplary results in the field of computer vision for the tasks of image-to-image translation but when it comes to working with linguistic data, GANs are still very new and trying to find their place. Text summarization is one of the few tasks where the application of GANs is being tested. The proposed model suggests a GAN architecture where a discriminator network teaches the generator network to synthesize summary text. The model is able to understand many underlying ideas in the summary. The dataset for this task can be found at Sent-Summary.
Liver Tumor Semantic Segmentation using SegAN
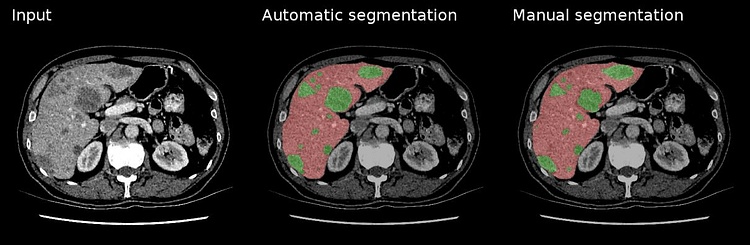
Fig. Liver Tumor Semantic Segmentation using GANs (Source)
One of the main causes of death from cancer across the world is hepatic cancer. Early diagnosis of cancer through CT Scans can prevent the death of millions of human beings around the globe. If deaths can’t be prevented, doctors can definitely extend the life expectancy with prolonged treatment. The limitation is that reading and analyzing the scans is a very labour-intensive and time-consuming task, making it very difficult for radiologists to keep up with the pace. Over the last decade, we have seen many advances in the technologies for analyzing medical images accurately and precisely with the help of advanced AI algorithms. Many startups are working dedicatedly towards the goal of making the lives of medical service providers easier with the help of AI-powered systems.
One of the ways to analyse the scans and identify the regions of abnormality is semantic segmentation. While deep and complex CNNs architectures have achieved remarkable results in the field of semantic segmentation, we can also use a special kind of GAN for the task called SegNet. The architecture of the SegNet is a bit complicated to understand and beyond the scope of this article. If you wish to learn more about it, you can refer to SegAN – Semantic Segmentation with Adversarial Learning. Broadly, it makes use of a critic-adversarial network using FCN as segmentor to learn the underlying long and short relationships between image pixels and generates segmentation maps for the same. If you are looking for a final-semester thesis, you can consider exploring this project in depth. You can use LiTS – Liver Tumor Segmentation Challenge dataset for this task.
https://github.com/alitourani/generative-adversarial-network
https://machinelearningmastery.com/generative_adversarial_networks/