
Run.AI is a company that specializes in enabling organizations to optimize and accelerate AI workloads in a more efficient manner. It provides a cloud-native platform designed to maximize the utilization of AI hardware infrastructure, particularly GPUs. By dynamically allocating GPU resources across multiple teams and workloads, Run.AI helps organizations manage their AI/ML infrastructure more effectively.
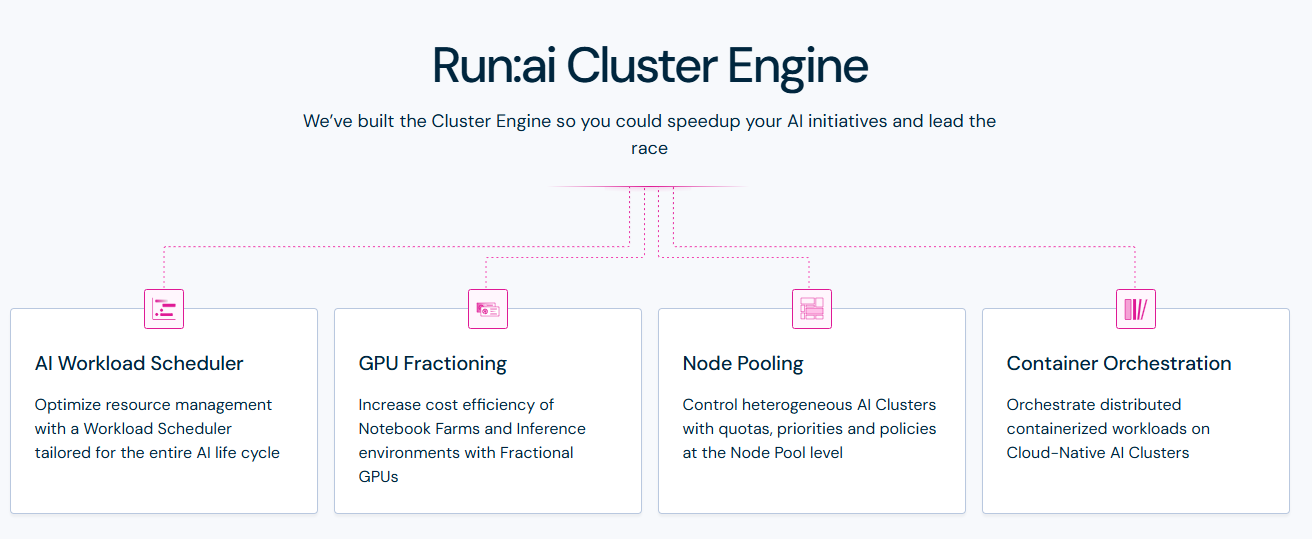
Dynamic Resource Allocation: Enables the efficient sharing of GPU resources across multiple users and workloads.
Kubernetes Integration: Leverages Kubernetes for container orchestration, allowing for scalable and flexible resource management.
Cluster Management: Centralized management of GPU clusters across on-premises, cloud, and hybrid environments.
Job Prioritization: Allows prioritization and queuing of AI workloads to meet business needs.
Elastic GPU Pools: Facilitates elastic allocation of GPUs for optimal utilization, reducing underused hardware.
Multi-Tenancy Support: Provides secure isolation between different teams or users.
Ease of Integration: Compatible with major AI/ML frameworks like TensorFlow, PyTorch, and others.
Few examples:
Submitting an AI/ML Job
Run.AI enables you to submit jobs to GPU clusters via its CLI or directly using Kubernetes YAML manifests.
CLI Example
bashCopy coderunai submit my-job \
--image tensorflow/tensorflow:latest-gpu \
--gpu 2 \
--command "python train.py --epochs=10"
--image: Specifies the container image for the job.--gpu: Allocates the number of GPUs required.--command: The command to execute within the container.
2. Kubernetes YAML Manifest Example
You can use Kubernetes manifests to submit jobs through Run.AI. Below is an example YAML file for a TensorFlow training job.
yamlCopy codeapiVersion: batch/v1
kind: Job
metadata:
name: tensorflow-training
annotations:
runai.io/project: "default"
spec:
template:
spec:
containers:
- name: tensorflow-container
image: tensorflow/tensorflow:latest-gpu
command: ["python", "train.py"]
resources:
limits:
nvidia.com/gpu: 2
restartPolicy: Never
- Annotations: Specify the Run:AI project for the job.
nvidia.com/gpu: Requests the number of GPUs for the container.
3. Elastic GPU Allocation
Run.AI supports elastic resource allocation. You can request a GPU fraction instead of an entire GPU for lightweight tasks.
Example YAML for Elastic Allocation
yamlCopy codeapiVersion: v1
kind: Pod
metadata:
name: elastic-gpu-job
annotations:
runai.io/project: "default"
spec:
containers:
- name: lightweight-task
image: pytorch/pytorch:latest
resources:
limits:
nvidia.com/gpu: 0.5 # Request half a GPU
command: ["python", "light_task.py"]
4. Job Monitoring
Run.AI provides tools to monitor your jobs using CLI or the web interface. Below is an example CLI command to check the status of a submitted job.
bashCopy coderunai list jobs
Output:
plaintextCopy codeNAME STATUS GPU(REQ/LIMIT) NODE
my-job Running 2/2 gpu-node-1
tensorflow-job Pending 1/1 -
5. Scheduling Priority
Run:AI allows job prioritization based on policies. Higher-priority jobs can preempt lower-priority ones.
Example: Setting Priority in YAML
yamlCopy codeapiVersion: batch/v1
kind: Job
metadata:
name: high-priority-job
annotations:
runai.io/project: "default"
runai.io/priority: "high"
spec:
template:
spec:
containers:
- name: high-priority-task
image: pytorch/pytorch:latest
resources:
limits:
nvidia.com/gpu: 1
6. Hybrid Cloud Integration
Run:AI enables hybrid cloud deployments. Below is an example of configuring a hybrid environment to use both on-premise and cloud GPUs.
Example Config
- On-premise nodes: Tag them with
runai.io/type=on-prem. - Cloud nodes: Tag them with
runai.io/type=cloud.
bashCopy codekubectl label nodes on-prem-node-1 runai.io/type=on-prem
kubectl label nodes cloud-node-1 runai.io/type=cloud
When submitting jobs, specify the node type:
bashCopy coderunai submit cloud-job --node-type cloud
https://www.run.ai/