
DensePose, dense human pose estimation, is designed to map all human pixels of an RGB image to a 3D surface-based representation of the human body. This is done through the introduction of a large-scale, manually annotated dataset, and a variant of Mask-RCNN, a simple, flexible framework for object instance segmentation.

Advances in computer vision and machine learning techniques have led to significant development in 2D and 3D human pose estimation from RGB cameras, LiDAR, and radars. However, human pose estimation from images is adversely affected by occlusion and lighting, which are common in many scenarios of interest. Radar and LiDAR technologies, on the other hand, need specialized hardware that is expensive and power-intensive. Furthermore, placing these sensors in non-public areas raises significant privacy concerns.
To address these limitations, recent research has explored the use of WiFi antennas (1D sensors) for body segmentation and key-point body detection. Use of the WiFi signal in combination with deep learning architectures, commonly used in computer vision, to estimate dense human pose correspondence.
Dense human pose estimation aims at mapping all human pixels of an RGB image to the 3D surface of the human body.
- We introduce DensePose-COCO, a large-scale ground-truth dataset with image-to-surface correspondences manually annotated on 50K COCO images.
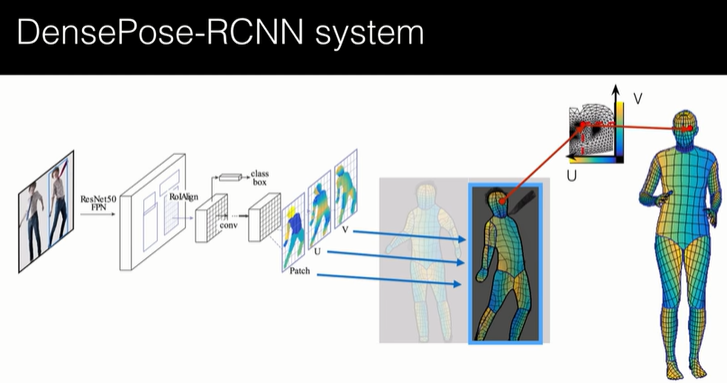
- We propose DensePose-RCNN, a variant of Mask-RCNN, to densely regress part-specific UV coordinates within every human region at multiple frames per second.
ArXiv
COCO is a widely used visual recognition dataset, designed to spur object detection research with a focus on full scene understanding. In particular: detecting non-iconic views of objects, localizing objects in images with pixel level precision, and detection in complex scenes. Mapillary Vistas is a new street-level image dataset with emphasis on high-level, semantic image understanding, with applications for autonomous vehicles and robot navigation. The dataset features locations from all around the world and is diverse in terms of weather and illumination conditions, capturing sensor characteristics, etc.
Mapillary Vistas is complementary to COCO in terms of dataset focus and can be readily used for studying various recognition tasks in a visually distinct domain from COCO. COCO focuses on recognition in natural scenes, while Mapillary focuses on recognition of street-view scenes. We encourage teams to participate in challenges across both datasets to better understand the current landscape of datasets and methods.
DensePose, dense human pose estimation, is designed to map all human pixels of an RGB image to a 3D surface-based representation of the human body. This is done through the introduction of a large-scale, manually annotated dataset, and a variant of Mask-RCNN, a simple, flexible framework for object instance segmentation
DensePose establishes dense correspondences between RGB images and a surface-based representation of the human body. To do this, AI researchers built DensePose-COCO, a large-scale, ground-truth dataset with image-to-surface correspondences annotated on 50,000 COCO images.
The DensePose-COCO dataset was used to train DensePose-RCNN, a CNN-based system that delivers dense correspondences “in the wild”, namely in the presence of complex backgrounds, occlusions, and scale variations. Portions of the DensePose research project will be open sourced soon.
DensePose-COCO Dataset
We involve human annotators to establish dense correspondences from 2D images to surface-based representations of the human body. If done naively, this would require by manipulating a surface through rotations – which can be frustratingly inefficient. Instead, we construct a two-stage annotation pipeline to efficiently gather annotations for image-to-surface correspondence.
As shown below, in the first stage we ask annotators to delineate regions corresponding to visible, semantically defined body parts. We instruct the annotators to estimate the body part behind the clothes, so that for instance wearing a large skirt would not complicate the subsequent annotation of correspondences.
In the second stage we sample every part region with a set of roughly equidistant points and request the annotators to bring these points in correspondence with the surface. In order to simplify this task we `unfold’ the part surface by providing six pre-rendered views of the same body part and allow the user to place landmarks on any of them. This allows the annotator to choose the most convenient point of view by selecting one among six options instead of manually rotating the surface.
We use the SMPL model and SURREAL textures in the data gathering procedure.

The two-stage annotation process has allowed us to very efficiently gather highly accurate correspondences. We have seen that the part segmentation and correspondence annotation tasks take ap- proximately the same time, which is surprising given the more challenging nature of the latter task. We have gathered annotations for 50K humans, collecting more then 5 million manually annotated correspondences. Below are visualizations of annotations on images from our validation set: Image (left), U (middle) and V (right) values for the collected points.
http://densepose.org/