
Dataiku enables teams to create and deliver data and advanced analytics using the latest techniques at scale.
Dataiku can be used by data scientists, but also business analysts and less technical people.
Dataiku is the platform for Everyday AI, systemizing the use of data for exceptional business results.
Dataiku can read and write in various file formats for files-based connections: filesystem, HDFS, Amazon S3, HTTP, FTP, SSH
Many applications such as Google Sheets, SalesForce, Slack, it provides capabilities to access their data through APIs. Dataiku DSS plugins allow the addition of custom connections leveraging these APIs to easily define datasets that fetch data from a wide variety of applications.
Dataiku belongs to “Data Science Tools” category of the tech stack, while Tableau can be primarily classified under “Business Intelligence”.
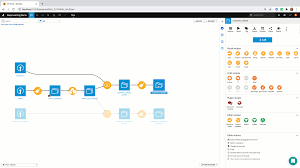
Dataiku DSS allows you to work with data that is structured or unstructured. Structured data is a series of records with the same schema. In Dataiku DSS, such data is referred to as a dataset. Unstructured data can have an internal structure, but the entries do not necessarily have the same schema.
Data Science Studio reads data from the outside world in “external” datasets. On the other hand, when you use the Data Science Studio to create new datasets from recipes, these new datasets are “managed” datasets. This means that Data Science Studio “takes ownership” of these output datasets. For example, if the managed dataset is a SQL dataset, Data Science Studio will be able to drop / create the table, change its schema, …
Recipes are the building blocks of your data applications. Each time you make a transformation, an aggregation, a join, … with DSS, you will be creating a recipe.
Recipes have input datasets and output datasets, and they indicate how to create the output datasets from the input datasets.
Data Science Studio supports various kind of recipes :
- Executing a data preparation script defined visually within the Studio
- Executing a SQL query
- Executing a Python script (with or without the use of the Pandas library)
- Executing a Pig script
- Executing a Hive query
- Synchronizing the content of input to output datasets
Managed datasets are created by Data Science Studio in “managed connections”, which act as data stores. Managed datasets can be created:
- On the filesystem of the Data Science Studio server
- On Hadoop HDFS
- In a SQL database
- On Amazon S3