
The goal is to achieve best AI training performance and support all these larger, more complex models and be power-efficient, and cost-effective at the same time.
It’s a Distributed Compute Architecture.
All the training computers out there are distributed computers in one form or the other, they have compute elements — in the box out here — connected with some kind of network, in this case it’s a two-dimensional network. But it could be any different network: CPU, GPU, accelerators, all of them have compute, little memory, and network.
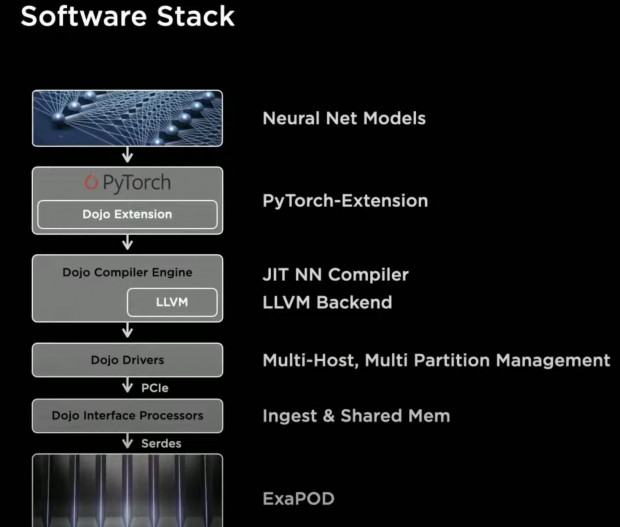
The stack consists of extension to PyTorch that ensures the same user-level interfaces that ML scientists are used to, and compiler generates code on-the-fly such that it can be re-used for subsequent execution. It has an LLVM Backend that generates the binary for the hardware, and this ensures it can create optimized code for the hardware without relying on even a single line of handwritten kernel.
Each D1 chip is made up of 354 functional units and each functional unit has only 1.25 MB of SRAM and no DRAM at all so there is less than ½ GB of memory per D1 processor. They have provisioned large DRAM pools on each end of a 5 rack row there is no DRAM in the compute racks themselves. In thinking through how they can operate so light on memory, I suspect it’s a combination of vast networking bandwidth and that the system is designed to run vision models where are less memory intensive than many other common ML training workloads.

Each D1 chip delivers 16,000 GBps (4 channels of 4Tbps) of networking and they are combined into 25 chip MCM (Multi-Chip Modules) to deliver 36,000 GBps (4x 9TBps) of network bandwidth.
Each D1 chip only dissipates 400 W which about as expected for a modern part of that size but they have combined these into fairly dense 25 chip MCMs called training tiles each of which dissipates 15kw (10kw of D1s and 5kw of voltage regulators and other overhead). That’s 1.8 megawatts for the full planned 10 rack Dojo training system. As a point of scale a mid-sized datacenter will run in the 30 to 40 megawatt range).
Dojo Processing Unit — a DPU consists of one or more D1 chips, it also has our interface processor and one or more hosts. This can be scaled up or down, as per the needs of any network running on it.